Last week I posted some observations based on using the Computer Vision API (part of the Azure Cognitive Services) in an attempt to read text content from complex images. For these experiments I’ve chosen to use Pokémon cards as they contain a large variety of fonts and font sizes, and do not use a basic grid for displaying all text.
Today I’ve taken some time to do a comparative test with the same images using the text detection feature within Google Cloud Vision API (which at the time of writing is also still in preview).
API Comparison
The simplicity of creating a test client was on-par with the Azure service, again requiring only three lines of code once the client library and SDK were installed.
There are a few observable differences in the way Google and Azure services have been constructed;
 Azure Computer Vision API attempts to break all text down to regions, lines, and words – while the Google Cloud Vision API only identifies individual words.
Azure Computer Vision API attempts to break all text down to regions, lines, and words – while the Google Cloud Vision API only identifies individual words.- Azure Computer Vision API attempts to identify the orientation of the image based on the words detected
- Azure Computer Vision API returns graphical boundaries as rectangles, while Google Cloud Vision API uses polygons. This allows the Google service to more accurately deal with angled text, and mitigates the lack of orientation detection.

Using the Google Cloud Vision API, the orientation could be derived based on the co-ordinates provided. Using the longest word returned one can generally assume that the longest side on the bounding polygon represents the horizontal axis of a properly orientated image.
The Google Cloud Vision API also makes an attempt to group all text into a single ‘description’ value containing an approximation of all the identified words in the correct order. This works well for standard text where the topmost point of the bound polygons for each word align – however images where the polygons are bottom-aligned (due to different font-sizes) the description is in reverse order.
Text Detection Comparison
The results comparison results varied from card-to-card, but overall on comparison of the two services the Google Cloud Vision API appears slightly more accurate.
Clean Image Comparison
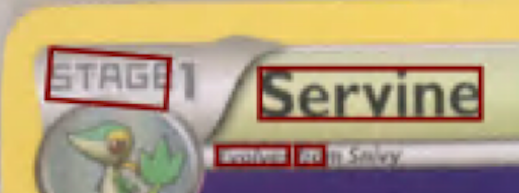
The following examples are an example of the results based on a ‘clean image’ – in this case Servine provided the best results in both APIs.
- Both APIs did a good job of reading clear blocks of text, including content in a very small (but non-italic) font.
- Neither service identified word ‘Ability’, presumably due to the font/style used.
- Neither service correctly identified the small/italic text correctly (Evolves from Snivy)
- Neither service identified the font change for the numeric ‘1’ in STAGE1
| Original Image | Azure | |

STAGE1 Servine
Evolves from Snivy |

STAGEI Ser vine
Evolves |
STAGE
Evolves fro |
NO. 496 Grass Snake Pokémon HT: 2’07” WT 35.5 lbs |

NO, 496 Grass Snake Pokémon HI: 2’07” WT: 35B lbs
|
NO, 496 Grass Snake Pokémon HT 2 O7 WT 35.3
|
| Ability Serpentine Strangle
When you play this Pokémon from your hand to evolve 1 of your Pokémon, you may flip a coin. If heads, your opponent’s Active Pokémon is now Paralyzed. |
When you play this Pokémon from your hand to evolve l of your Pokémon, you may flip a coin. If heads, your opponent’s Active Pokémon is now Paralyzed |

When you play this Pokémon from your hand to evolve l of your Pokémon, you may flip a coin. If heads |
Lower Quality Images
Lower quality images resulted in much bigger differences between the Vision APIs provided by Azure and Google, with the Google Cloud Vision API providing much more accurate text recognition.
| Original Image | Azure | |

They photosynthesize by bathing their tails in sunlight. When they are not feeling well, their tails droop.
|

their tails in trot
|

rhey photosynthesize bybathinv their tails in sunlight, when they
are not feelinu well, their tails droop. |
| Basic Machamp-EX HP180
|
Basic Machamp
|
Basic Machamp
|

Pokémon-EX rule
When a Pokémon-EX has been Knocked Out, your opponent takes 2 Prize cards. |
Pokémon-EX rule
Wheoa Pokémon•EX has your opponent takes 2 Prue |

Pokémon-EX rule
When a Pokémon Exhas been Knocked out, your opponent takes 2 Prize cards. |

If its coat becomes fully charged with electricity, its tail lights up. It fires hair that zaps on impact.
|

l/ its coat becomes fully ch.itxed 9ith electricity, its tail lis’hts up. It fires hair that zaps ort impact.
|

If its coat becomes fully charged with electricity, its tail lights up. lt fires hair that zaps on impact.
|
Conclusion
Although the Azure Computer Vision API does include more helpful features (such as identifying image orientation and pre-grouping regions and lines of text), the text detection exhibited by the Google Cloud Vision API was far more accurate when using lower-quality images.

[…] In a more recent post I’ve taken a look at the comparison of the results for these images using the Google Cloud Vision API. Take a look at my follow up post Quick look at Text Detection in the Google Vision API. […]